Fedoras - Catalog Import for Continuous Inventory Accuracy
Fedoras

Fedoras - Catalog Import for Continuous Inventory Accuracy
Introduction
Fedoras.com, a U.S.–based accessories retailer with rapidly expanding B2B and DTC channels on Shopify Plus, was hitting a hard ceiling: every new product drop or supplier restock required merchandisers to juggle error‑prone CSV files, wait hours for bulk inventory updates to finish, and then chase down mismatched SKUs across multiple warehouse locations. Internal logs showed that manual flat‑file imports consumed ~20 operations hours per month and triggered a 3 % SKU‑mismatch rate, translating into reducing stock‑outs, canceled orders, and lost revenue during peak seasons.
The pain intensified as Fedoras opened regional fulfillment nodes to improve two‑day delivery across North America. Each new location multiplied the complexity of inventory synchronisation—yet Shopify’s native admin allowed only one inventory upload at a time. What the brand needed was geo‑aware, high‑throughput inventory syncing that scaled with its multi‑location strategy while keeping inventory data “five‑nines” accurate.
MLVeda delivered an embedded, API‑driven solution that enables faster inventory turnaround through bulk inventory updates, turning supplier CSVs into validated, location‑aware updates in under 30 minutes—setting the foundation for a broader Shopify B2B accelerator now being rolled out across our B2B client base. This automated solution ensures inventory replenishment automation, minimizing stock discrepancies and allowing Fedoras.com to keep inventory levels synchronized in real time.





Challenges – The Hidden Friction Behind Inventory Accuracy
Fedoras.com had modernized its front‑end on Shopify Plus, yet its inventory engine still ran on nightly CSV uploads. Every supplier restock forced merchandisers to reconcile mismatched columns, babysit long‑running imports, and then patch stock errors across five U.S. and Canadian distribution centers—a process that consumed ~20 operations hours per month and drove a 3 % SKU‑mismatch rate. As order volumes grew, flat-file workflow latency and lack of real-time inventory updates hindered revenue growth, delayed product drops.

Collectively, these bottlenecks throttled Fedoras.com’s ability to scale its Shopify Plus B2B program across North America. Fixing them would require a location‑aware, schema‑validated import pipeline capable of turning flat files into “five‑nines” inventory accuracy—without adding headcount or slowing product launches
Solution – API-Driven, Location-Aware Catalog Import
To erase flat-file friction, MLVeda engineered an embedded Catalog Import application that lives inside the Shopify Plus Admin, validates supplier CSVs in real time, and posts inventory updates to every U.S. and Canadian distribution center in a single, fault-tolerant run. The design principle: treat every import like code—tested, versioned, and idempotent.

- Drag-and-Drop Upload UI
- Polaris-based React component lets merchandisers choose a vendor, select up to 20 CSVs at once, and map each file to one or more Shopify Location IDs—no spreadsheet gymnastics.
- Polaris-based React component lets merchandisers choose a vendor, select up to 20 CSVs at once, and map each file to one or more Shopify Location IDs—no spreadsheet gymnastics.
- Schema-Aware Validation Layer
- JSON-schema engine confirms header order, data types, and mandatory fields (SKU, Location ID, On-Hand Qty, Cost).
- Row-level errors surface instantly; files that fail validation never reach Shopify.
- Serverless Import Orchestrator for Bulk Inventory Updates
- AWS Lambda parses validated CSVs and pushes them to GraphQL Bulk Operations, achieving ~4,000 mutations per minute without hitting rate limits.
- AWS SQS queues and de-duplicates jobs, ensuring idempotent updates even if the same SKU appears in multiple files.
- Incremental & Absolute Stock Logic
- Merchandisers pick “Replace” or “Delta” mode. Replace wipes and rewrites counts; Delta applies net changes—solving the stale-file issue that once caused phantom oversells.
- Merchandisers pick “Replace” or “Delta” mode. Replace wipes and rewrites counts; Delta applies net changes—solving the stale-file issue that once caused phantom oversells.
- Real-Time Progress & Observability
- Web-socket progress bar shows rows processed, success/failure counts, and ETA.
- Structured logs stream to Datadog; error thresholds trigger Slack alerts and automatic Lambda retries.
- Multi-Vendor Extensibility
- New suppliers plug in via a YAML config: header map, delimiter, and unique validation rules—no code merge required.
- Architecture already sized for sub-minute webhook feeds, future-proofing the move from batch to real time.
This API-driven pipeline cuts import cycle time from hours to <30 minutes, slashes SKU mismatches to <0.2 %, and scales effortlessly as Fedoras.com adds new suppliers or distribution hubs across North America.
Key Components - Architecture Built for Scale and Accuracy
The Catalog Import solution for Fedoras.com was designed with modularity, fault tolerance, and extensibility as first principles. Each component played a critical role in transforming flat-file chaos into a reliable, location-aware inventory pipeline that fits seamlessly into Shopify’s B2B ecosystem.



Together, these components deliver a purpose-built inventory management layer on top of Shopify that eliminates SKU mismatches, reduces human error, and dramatically shortens the time from vendor file to live inventory.
Implementation – Rapid, Low‑Risk Rollout in Four Controlled Waves
The implementation approach emphasized speed to first value, data integrity, and repeatable scale. We treated the Catalog Import capability as a mini‑platform build rather than a one‑off script—establishing clear quality gates, observability, and extensibility from day one.
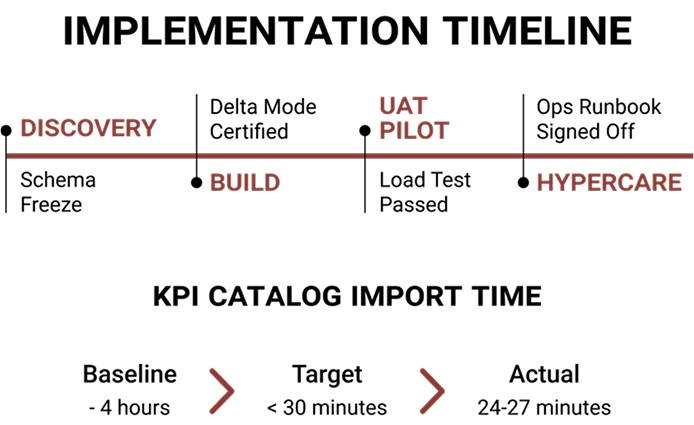
Discovery & Specification (Day 1)
Key Decisions:
Adopt a versioned JSON schema (v1.0) with forward‑compatible optional fields; introduce Delta mode to avoid stale full‑file overwrites; enforce location mapping at upload (not post‑processing).
Build & Internal QA (Days 2–11)
Test Coverage:
80%+ logic branches; synthetic load test (10 simultaneous imports, 50k total rows) under targeted runtime budget (<30 min end‑to‑end).
UAT & Controlled Pilot (Days 12–16)
Slack alerts verified (start, 50%, completion, anomaly). Latency / error dashboards approved by ops and merchandising leads.
Production Launch & Hypercare (Days 17–20)
Rollback plan:
Toggle feature flag to freeze new imports; replay last “known good” Dynamo snapshot with Replace mode. RTO (Recovery Time Objective) < 15 minutes.
Implementation Principles (Embedded for Ongoing Scale)
KPI Baselines Set During Implementation
Results – 2 Weeks In
Within the first two weeks of deployment, Fedoras.com saw clear improvements across every operational KPI tied to bulk catalog updates, inventory accuracy and inventory management. These changes also led to significant operational cost reduction, with a decrease in manual data handling and the labor-intensive nature of previous inventory management workflows, particularly benefiting Shopify Plus B2B retailers operating across multi-location North American fulfillment centers.
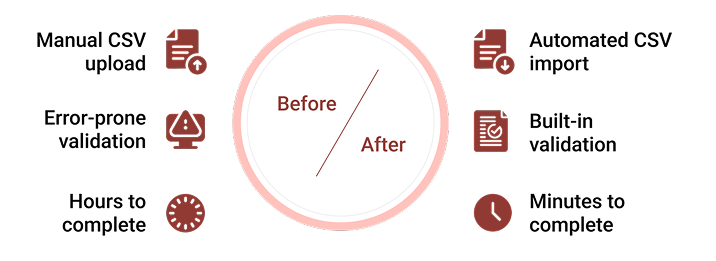
Quantitative Outcomes
Operational & Strategic Wins
Best Practices & Key Takeaways
Fedoras.com’s success with automated catalog import wasn’t accidental. It was the result of targeted architectural choices, early validation of assumptions, and a relentless focus on operational edge cases. These practices are broadly relevant to Shopify Plus merchants managing high-SKU inventories across multiple warehouses or suppliers.
1. Validate Before You Import
Why it matters: Flat files from vendors are inherently untrustworthy.
What worked: JSON-schema validation on the client and server side with row-level error messages.
Takeaway: Catching errors before ingestion saved 90% of downstream fire drills and preserved the integrity of inventory records.
2. Design for Idempotency from Day One
Why it matters: Catalog import will fail. What matters is how gracefully they recover.
What worked: Every job, file, and SKU-location update used a deterministic key structure to ensure safe retries.
Takeaway: Idempotency eliminates the fear of reprocessing and supports automated rollback strategies.
3. Treat Inventories as Multi-Dimensional Objects
Why it matters: Shopify’s native tools assume a single inventory, single location model. Real B2B environments rarely work that way.
What worked: Upload UI required location mapping per file; processing logic routed SKUs to the correct Shopify location IDs.
Takeaway: Inventory must be location-aware and vendor-scoped to enable regional fulfillment and cross-border compliance.
4. Make Progress Observable, Not Just Executable
Why it matters: Ops teams lose trust when they’re left guessing.
What worked: Live dashboard with percent complete, error count, and Slack alerts at key thresholds.
Takeaway: Visibility builds confidence and reduces the need for manual spot-checks before product drops.
5. Use Config, Not Code, for Extensibility in Automated Inventory Management
Why it matters: Every new vendor should not be a dev ticket.
What worked: Vendor templates were defined via YAML: header mappings, column types, import thresholds.
Takeaway: Treating onboarding as a configuration task empowered non-technical users and cut cycle time from days to minutes.
6. Give Merchandising Control Without Engineering Bottlenecks
Why it matters: Merch teams need autonomy to launch and update without risking inventory accuracy.
What worked: Embedded UI in Shopify Admin with no external login or middleware console.
Takeaway: Putting control where users already work shortens ramp-up time and minimizes process errors.
7. Plan for What’s Next (Not Just What’s Broken)
Why it matters: Solving today’s pain shouldn’t create tomorrow’s rigidity.
What worked: The architecture supports both bulk CSV uploads and webhook-based real-time updates.
Takeaway: Build now, but don’t block evolution—especially as Shopify B2B expands its native Functions and Credit APIs.
Conclusion – From Flat Files to a Scalable Inventory Ops Platform
Fedoras.com’s catalog import challenge was never just about files—it was about unlocking operational agility at scale. By replacing fragmented spreadsheets and manual corrections with a fault-tolerant, location-aware pipeline embedded directly in the Shopify Plus Admin, the brand now manages inventory with near real-time accuracy across five distribution centers and eight active vendors.
The project eliminated hours of repetitive effort, surfaced data issues before they reached production, and gave the merchandising team the confidence to launch new product lines without fear of stockouts or silent failures. More importantly, it laid the foundation for B2B growth: batch uploading location-specific inventories, onboarding vendors in hours not days, and preparing for the eventual rollout of Shopify-native credit, payment, and fulfillment capabilities.
What Comes Next — MLVeda’s B2B Accelerator
This implementation now powers the core of MLVeda’s Shopify B2B Accelerator, a modular solution stack designed to address key platform gaps for manufacturers, distributors, and high-SKU retailers. Future roadmap items include:
- Store Credit & Conditional Payment Terms
Logic to handle customer-specific credit limits, store credit balances, and dynamic payment methods at checkout (using Shopify Functions and Payment Extensions as they mature) - Split Shipments & Location-Aware Pricing
Inventories will support price and stock differentiation by fulfillment center—especially useful for brands operating in both U.S. and Canada - Webhook-Based Real-Time Updates
Transitioning from CSV batch uploads to continuous inventory syncing using supplier system webhooks or middleware integrations - Admin-Controlled Access Rules
Allowing team-based permissions around inventory ingestion, rollback, and audit trail visibility
Fedoras.com’s success story is not an endpoint—it’s a reference architecture for how the Shopify B2B ecosystem can evolve beyond native limitations and toward fully automated, multi-location, multi-vendor operations.
We’re Listening
Whether you're exploring strategic transformation opportunities or seeking a partner to architect and execute enterprise technology initiatives, we're here to help. Reach out to our team at services@mlveda.com or complete the form to begin the conversation.
